
Xplan Xplained
Existing Insurance reference guide
Everybody loves Insurance
Having the clients existing data in the system is half the battle won.
If you’re struggling to remember how to or just wondering why there are so many different ways to code insurance, wonder no more as we’re going to go through a lot of them! Areas covered:
- Structure of the insurance data and code;
- Policy information;
- Cover information;
- Risk Researcher and cover data;
The structure of the insurance data
The Insurance section can be thought of, both in coding and how the data is stored, as being broken up in much the same way as what you see in Xplan:
- Policy Section – This is the header information for the entire policy. When you click add or edit for an insurance policy, everything you can see and edit here would be the policy (top level information) and can generally be accessed by iterating over one of the insurance elements.
- Covers Section – This is all the underlying cover information, so all the specific details about the relevant life, tpd, trauma, income, business expense, severity cover that is accessed by clicking add or edit within a policy under the covers tab. It’s essentially a sub section of each policy and this data is generally accessed by the covers() item within the insurance element so just as it is in the interface it’s a sub section in the coding too.
Keep this in mind for finding information, coding and if questions of where to storage data come up, knowing this can ensure you build and guide clients to solutions that work with the system and stand the test of time.
Insurance Policy Information (Top level header data)
Like so many things in Xplan there are of course a variety of ways we can start to access the top level insurance information. This is where you need to consider what you want to show and what the purpose of the report or document you are creating is. How the adviser wants to show the data can also affect the approach you take with the coding (some advisers have strong views on showing insurance by life insured vs policy owner).
By Cover (<:for item in $client.insurance_by_cover:>)
- Outputs all policies that the client is the Life Insured for
- Separates the $client and $partner policies respectively
- Same data as what you see in your xplan site if you look at Insurance by cover or Insurance by life Insured (xplan element but in most sites by default under Insurance > Existing)
- Because its based on the life insured any policies held by Super Funds or other entities will also appear.
- Because the life insured is always one individual not affected by jointly owned policies either
This can be a popular one to use particularly in advice documents where the tools and conversation is usually based around the need or cover for the life insured.
By Policy (<:for item in $client.insurance_by_policy:>)
- Outputs all policies that the client is the Policy Owner for
- Output should match what you see in existing insurance ‘By Policy owner’
- Separates the $client and $partner policies respectively
- Joint owned policies will show up under both
- Entities will need to be coded in. Eg if the clients SMSF is the owner of the policy it won’t come through in the $client or $partner code you’ll need to iterate over the related entities.
Depends on the document and the adviser, but the data has to align with the purpose. Eg a policy renewal document will go to the policy owner and so the information displayed needs to be in this context as well.
All Insurance Group (<:for item in $client.all_insurance_group:>)
- Outputs all policies for the Client and Partner (by just $client)
- Good for documents where the formatting or document isn’t broken up by Client / Partner. Eg a policy schedule or basic fact find might just want to show one table of all the policies.
- Will go over client policies first then partner.
- Joint owned policies will only show up once
- Entities will need to be coded in.
If the format or document doesn’t require the tables be separated by Client / Partner, maybe because Policy Owner and Life Insured are already shown in the table or its an overview document then this can potentially make things easier.
Filtering
Many elements and groups in in Xplan can use the basic .filter(), as you can on any of the 3 above, to limit the results to the relevant criteria set.
The most common type applied is usually .filter(‘policy_status=Inforce’):
<:for item in $client.insurance_by_cover.filter(‘policy_status=Inforce’):>
# This way only the policies that are inforce will come through.
<:end:>
The above is generally the preferred filtering option, however you need to keep in mind a) how the business has been using the system and recording data b) the context of whatever document you are building.
There are a lot of statuses in the Policy Status drop down list, whilst Inforce is the way the system works and generally the preferred approach, clients who have been using Xplan for a while may be recording data in all sorts of ways that you may need to account for.
For example in some instances you may need to show policies marked as ‘Existing’ or ‘Paid Up’ ‘Extended Term’ etc. Alternatively it may be preferable to just filter out the policies they definitely won’t want to see in the context of the document. To do that we need to move beyond the basic filter option and use something like:
<:for item in [policy for policy in $client.insurance_by_cover if str(policy.policy_status.value) in [‘Inforce’, ‘Existing’,’Paid Up’]]:>
# I’m only going to output policies marked as Inforce, Existing, Paid Up.
<:end:>
Or to exclude certain policies
<:for item in [policy for policy in $client.insurance_by_cover if not str(policy.policy_status.value) in [‘Void’, ‘Cancelled’, ‘Lapsed’, ‘Inactive’, ‘Declined’]]:>
# Policies not equal to void, cancelled, lapsed, inactive…will be merged
<:end:>
Sorting
Just like filtering you can also sort any of the header items. Some form of structure or logical order can make interpreting and reading data easier for the reader (eg the clients client) so it doesn’t hurt anything to throw in a sort of some kind eg by underwriter or premium.
<:for item in $client.insurance_by_cover.filter('policy_status=Inforce').sort(‘coy’):># policies will come out alphabetically based on the undwriter. Eg AIA, AMP, MLC, Zurich.
or
<:for item in $client.insurance_by_cover.sort(‘benefit_premium’):>
# Policies will be sorted lowest premium to highest
Add in the minus sign to any sorting to reverse the order eg .sort(‘-benefit_premium’) will become highest to lowest.
Policy Data
So just about anything you can see in the header screen can be merged from here so going through it section by section
<:for item in $client.insurance_by_cover.filter(‘policy_status=Inforce’).sort('coy'):>
| Data . |
Code . |
Notes . |
|
| Type |
|
Usually always term but you can select Whole of Life (WoL) or endowment to access contract value cover options | |
| Underwriter |
|
||
| Plan Name |
|
||
| Policy Number |
|
A lot of admin don’t record these, its well worth taking the time, the more data you put in your system the less you have to look elsewhere. Existing insurance or policy information letters look better with this key bit of information and if its in the system it can be automatically merged out. | |
| Policy Status |
|
||
| Under Advice |
|
||
| Total Premium |
|
When set at the policy level this is the premium(inside+outside)+policy fee – premium waiver amounts | |
| Premium Frequency |
|
||
| Annualised Premium |
|
||
| Life Sum Insured |
|
||
| TPD Sum Insured |
|
||
| Trauma Sum Insured |
|
||
| Income protection benefit |
|
This will give you the full amount so benefit amount * frequency. You will need to manually divide by frequency for the monthly amount | |
| Business Expense Benefit |
|
||
| Severity Based Insurance |
|
Also known as key body system |
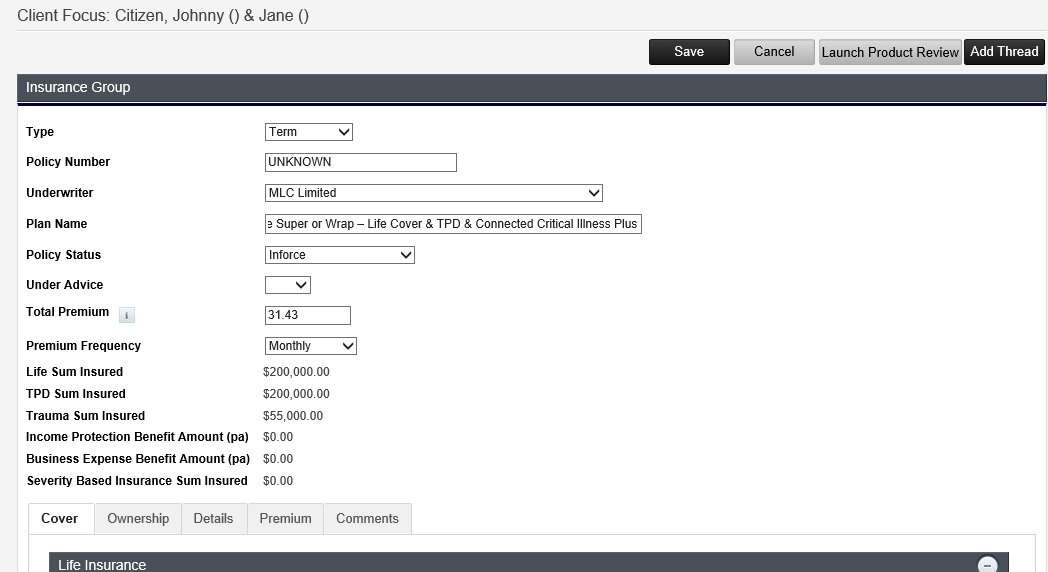
Continued (Ownership tab)
| Data . |
Code . |
Notes . |
|
| Policy Owner |
|
Ideally use the Owners list below | |
| Policy Owners |
|
This allows you to record multiple actual entities to the policy and links them. | |
| Group Plan |
|
||
| Super Fund |
|
Make sure to condition this or test on item.super_fund_id else it will error if no fund. | |
| Beneficiary |
|
You will need to use the entity_id if you want to present the name in a better style, eg first name, last name or preferred name. |
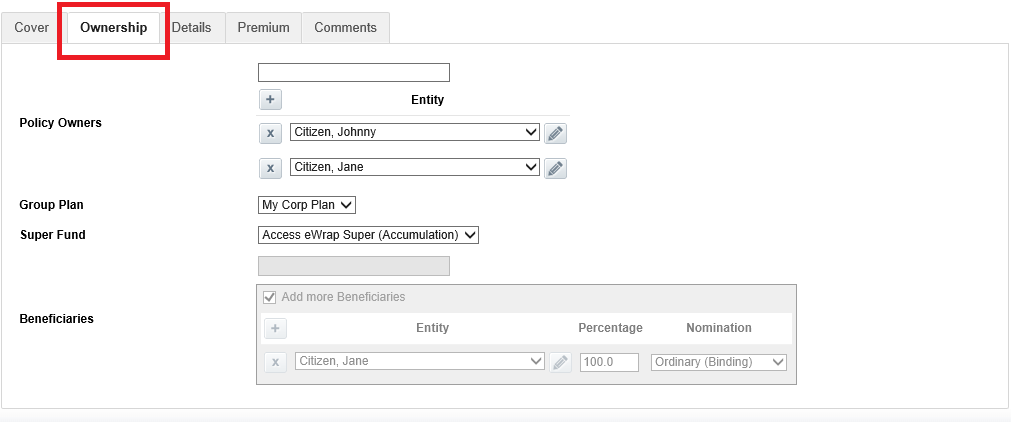
Continued (Details tab)
| Data . |
Code . |
Notes . |
|
| Start Date |
|
Can apply date formatting to end to customise output | |
| Premium end date |
|
This allows you to record multiple actual entities to the policy and links them. | |
| Next Review Date |
|
Common field to base for review searches/reports. | |
| Policy Purpose |
|
Rarely used item. Only the Business Insurance module relies and sets this field (Business protection then specific policy purpose that opens up). | |
| Values Last Updated |
|
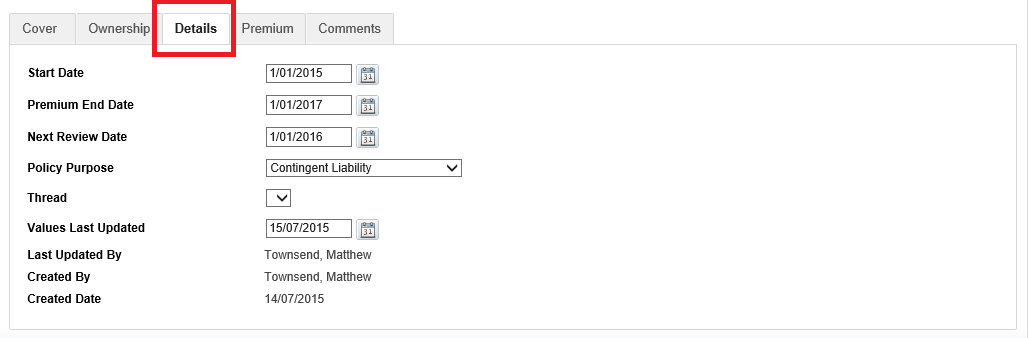
Continued (Premium tab)
| Data . |
Code . |
Notes . |
|
| Premium Payer |
|
Policy owner = payer always set to default and usually the case | |
| Payer is policy owner |
|
Bool Field 1 = True/Ticked/Enabled | |
| Payment Method |
|
If you have recorded the clients bank details in client focus you can link into those through here. | |
| Premium Waiver |
|
||
| Policy Fee |
|
||
| Set Premium at policy level |
|
Bool fieldTicked by default, if you untick it, premium options will open up in each individual cover. The sum of those will be used to calculate the total premium.With the 2.15 ability to get premium amounts for individual covers in risk researcher using cover premiums may become more popular. | |
| Premium Inside Super |
|
Showing the client the costs inside/outside super have become popular for a variety of reasons these new fields help facilitate that and will likely become more common in the future. | |
| Premium Outside Super |
|
||
| Commission Premium (pa) |
|
||
| Supplier Revenue |
|
If you implement from Risk Researcher this will be the 1st year commission percent |
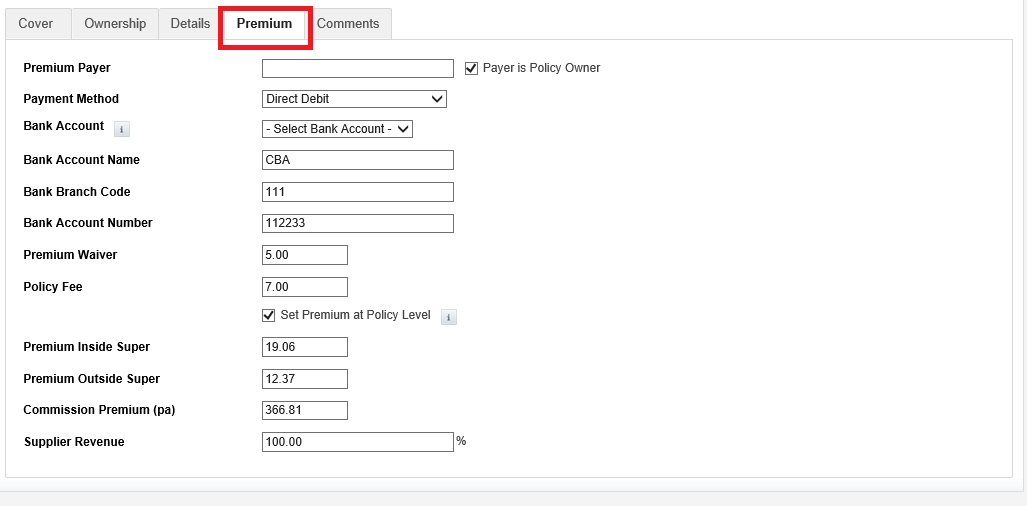
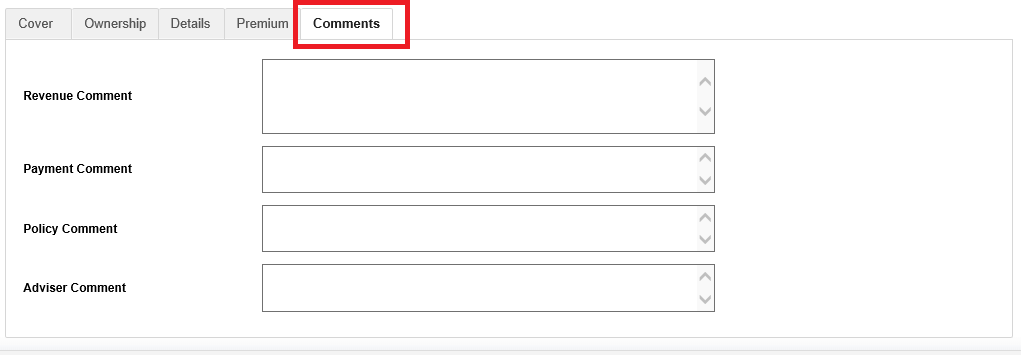
Continued (Comments tab)
| Data . |
Code . |
Notes . |
|
| Revenue Comment |
|
Used to store basic revenue info at policy level | |
| Payment Comment |
|
Payment notes if needed | |
| Policy Comment |
|
Store basic details regarding the policy | |
| Adviser Comment |
|
Clients using the system for a long time may use this field for adviser information. |
<:end:>
Detecting underlying cover (has_cover())
At this level there is also a nice argument based function to detect if the policy has a certain type of underlying cover eg does this policy contain life insurance? There are a few ways we could extrapolate this, eg if there is a sum insured amount there must be cover for that amount, we could also len item.covers() but an easier method is to just use:
<:=item.has_cover('l'):>
# True
has_cover returns a true or false based on the argument given use ‘l’, ‘d’, ‘t’, ‘i’, ‘b’ accordingly (see arguments further below).
Cover Information (cover tab/sub data)
Getting into the meat or the really key areas of an insurance policy is the cover data.
Just like when you enter or edit a policy, the cover information is all the cover specific items you find under the ‘covers’ tab. Information at this level includes, waiting periods, direct sum insured amounts, life insured, flexi status, definitions etc.
.Cover ()
All of this is accessed via .covers() within the main policy loop. The common coding for this is:
<:for item in $client.insurance_by_policy.filter('policy_status=Inforce'):>
<:for item2 in item.covers():>
# Now in the covers level and can access info stored within individual covers
<:end:>
<:end:>
Arguments
Within the brackets of .cover() we can add in arguments for essentially filtering out the type of cover we want to access:
Life = ‘l’
TPD = ‘d’
Trauma = ‘t’
Income protection = ‘i’ (Be aware of word capitalising this on you when coding)
Business expenses = ‘b’
Rider / Other = ‘o’
Severity / Key Body System = ‘k’
<:for item2 in item.covers(‘l’):>
# only life covers under this policy (item) will come through
<:end:>
This is useful for a few things depending on how you are building your tables or the data you are trying to access. For example just running .covers() with no arguments will work but it won’t bring your data through with any (discernible) structure to the reader eg one policy will merge in order of tpd, life, trauma, the next trauma, life, tpd usually better to keep it consistent Life, TPD, Trauma, Income something like that.
Even if ordering wasn’t a good reason there is different data between the covers. Eg Life, TPD and Trauma share a different sum insured field to income protection and business expenses so in some way or another you are going to need to filter or identify different policy types.
Additional filtering within the sub level
To prevent exceptions, system errors or outlier data sometimes it doesn’t hurt to add in some additional redundancy. An example of outlier data:
- When using by_cover we might assume that only covers where the client is the life insured are merging through but its actually identifying policies where the client is the life insured so in the rare cases where a policy might contain different life insured’s the cover will still merge out regardless.
So we need to add a life insured check to ensure that only cover for the client comes through as the user would expect and some filtering to:
<:for item in $client.insurance_by_cover.filter('policy_status=Inforce'):>
<:for item2 in item.covers('i'):>
<:if item2.life_insured.value==$client.entity_id:># now only income protection policies the client is the life insured for will ever merge, regardless of any other cover added into the policy.
<:end:>
<:end:>
<:end:>
If you feel its still readable you can compress that down to:
<:for item2 in [cov for cov in item.covers('i') if cov.life_insured.value==$client.entity_id]:>
<:end:>
Cover Data
Below are all the codes for when you hook into the individual underlying covers or via .covers(). The first table for life shows everything the subsequent areas on show unique fields for those types
<:for item in $client.insurance_by_cover.filter(‘policy_status=Inforce’).sort('coy'):>
<:for item2 in [cov for cov in item.covers('l') if cov.life_insured.value==$client.entity_id]:>
| Data . |
Code . |
Notes . |
|
| Type |
|
Term by default. Can set a range of Life policy types here minor options will alter based on this. | |
| Type Group |
|
System based name for the type of insurance | |
| Sum Insured |
|
On some versions you may need to add the float to the currency code even when using value otherwise it will report 0 (2.13, 2.14) | |
| Life Insured |
|
Life Insured now links into the full entity naming so you can format this better and there’s no need to hook in via the $entity method. Can still do that if you needed though | |
| Benefit Status |
|
||
| Premium Structure |
|
||
| Description |
|
Based field to store additional description if needed. In the past used to be used to add more specifics about the cover but proper fields for all that now. | |
| Cover Escalation |
|
||
| Is Super |
|
Bool field | |
| Owner |
|
On the final page of risk researcher where you can choose the owner of each cover item, this is the field that will reflect that if you implement from RR. The dominant owner will be the one reflected at the policy level. | |
| Renewal Date |
|
Default date just merged as day month, so use date formatting if needed. | |
| Issue Date |
|
||
| Submit to Underwriter |
|
A way to record the date your office lodged with underwriter. Can be handy depending on how your offices processes are setup | |
| Expiry Date |
|
||
| Loadings expiry date |
|
||
| Exclusions expiry |
|
||
| Maturity date |
|
Based on the type of life cover selected, this field may become visible. | |
| ————- |
|
||
| Issue Status |
|
Use this to record if any loadings were added | |
| Based Sum Insured |
|
||
| Cash Surrender Value |
|
||
| Loan Value |
|
Applicable to some types of cover (type) | |
| Total Bonus |
|
Applicable to some types of cover (type) | |
| ———– |
|
||
| Notes |
|
||
| Exclusions Notes |
|
Can record any specific exclusions here | |
| Loading notes |
|
Record any loading info for this specific cover if needed |
Continued (Premiums tab when set at policy level unticked)
| Data . |
Code . |
Notes . |
|
| Instalment Premium |
|
If you want to record and show the premium for each line item of cover, untick ‘set at premium’ in the policy section and you will see this detail available. In 2.15+ implementing from RR should fill these details for each cover item. | |
| Premium Escalation value |
|
||
| Premium Escalation type |
|
<:end:>
<:end:>
Continued (Tpd)
<:for item in $client.insurance_by_cover.filter(‘policy_status=Inforce’).sort('coy'):>
<:for item2 in [cov for cov in item.covers('d') if item2.life_insured.value==$client.entity_id]]:>
| Data . |
Code . |
Notes . |
|
| Type |
|
Important, this is where the definition or type of TPD is recorded. | |
| Type Group |
|
System based name for the type of insurance | |
| Flexi-Linked |
|
Can be set based on the type of TPD. | |
| Super linked policy |
|
||
| ———- |
|
||
| Buy Back |
|
Bool field to record if buy back is an option on this cover | |
| Double TPD |
|
||
| Stand Alone |
|
<:end:>
<:end:>
Continued (Trauma)
<:for item in $client.insurance_by_cover.filter(‘policy_status=Inforce’).sort('coy'):>
<:for item2 in [cov for cov in item.covers('t') if item2.life_insured.value==$client.entity_id]]:>
| Data . |
Code . |
Notes . |
|
| Type |
|
Use this to record if base, comprehensive or linked to super trauma. | |
| Type Group |
|
System based name for the type of insurance | |
| Flexi-Linked |
|
Can be set based on the type of TPD. | |
| ———- |
|
||
| Buy Back |
|
Bool field to record if buy back is an option on this cover | |
| Reinstatement |
|
||
| Accelerated |
|
||
| Standalone |
|
<:end:>
<:end:>
Continued (Income Protection)
<:for item in $client.insurance_by_cover.filter(‘policy_status=Inforce’).sort('coy'):>
<:for item2 in [cov for cov in item.covers('i') if item2.life_insured.value==$client.entity_id]]:>
| Data . |
Code . |
Notes . |
|
| Type |
|
Record if basic or comprehensive IP | |
| Type Group |
|
System based name for the type of insurance | |
| Definition |
|
Important field to make sure is recorded. | |
| Benefit Amount |
|
Note: Income and Business pull the cover amounts or sum insured from different fields | |
| Benefit Frequency |
|
Monthly by default but if different make sure this is recorded accurately some templates may assume monthly but not always the case. | |
| Accident/Benefit Period |
|
Key to record for IP | |
| Waiting Period |
|
Key to record for IP | |
| ———- |
|
||
| Sickness Period |
|
use if the policy has different provisions for accident/sickness. usually both should be the same | |
| Accident Short Wait |
|
Can record if the cover has a short wait period option with it | |
| Indexed Claim benefit |
|
||
| Retrospective Claim |
|
<:end:>
<:end:>
Continued (Business Expenses)
<:for item in $client.insurance_by_cover.filter(‘policy_status=Inforce’).sort('coy'):>
<:for item2 in [cov for cov in item.covers('b') if item2.life_insured.value==$client.entity_id]]:>
| Data . |
Code . |
Notes . |
|
| Type |
|
Record if basic or comprehensive | |
| Type Group |
|
System based name for the type of insurance | |
| Benefit Amount |
|
Note: Income and Business pull the cover amounts or sum insured from different fields | |
| Benefit Frequency |
|
Monthly by default but if different make sure this is recorded accurately. | |
| Waiting Period |
|
||
| ———- |
|
||
| Sickness Period |
|
||
| Accident Short Wait |
|
Can record if the cover has a short wait period option with it |
<:end:>
<:end:>
Continued (Additional Rider Benefit)
<:for item in $client.insurance_by_cover.filter(‘policy_status=Inforce’).sort('coy'):>
<:for item2 in [cov for cov in item.covers('o') if item2.life_insured.value==$client.entity_id]] #Note for child cover rider's the life insured could be different depending on how the data is being recorded:>
| Data . |
Code . |
Notes . |
|
| Type |
|
Key to setting for riders | |
| Type Group |
|
System based name for the type of insurance | |
| Sum Insured |
|
||
| Benefit Frequency |
|
<:end:>
<:end:>
Continued (Severity / Key Body System)
<:for item in $client.insurance_by_cover.filter(‘policy_status=Inforce’).sort('coy'):>
<:for item2 in [cov for cov in item.covers('k') if item2.life_insured.value==$client.entity_id]]:>
| Data . |
Code . |
Notes . |
|
| Type Group |
|
System based name for the type of insurance | |
| Sum Insured |
|
||
| Additional Death Cover |
|
<:end:>
<:end:>
Risk Researcher data and existing policies
One of the best tips around data entry for those businesses who do insurance and especially for those who specialise it, is not only using Risk Researcher, but once the client accepts your recommendations and the cover becomes active, go back into your risk researcher scenario and click ‘Implement’
This will push all the data from your recommendations and place it into the existing insurance for you, this does a few good things:
- You know the data is going to be recorded the same way as the system uses it, ensuring high compatibility and best practice
- It automatically links the policy with the Risk Researcher data base so when you go to review the clients product, that’s one less manual step and one more bit of automation
- If you use the Risk Researcher correctly and indicate if you are including options like Future Insurability, Claims indexation, Child Trauma, Accident benefit etc all of that will get pushed to your existing policies as well. This makes it even more powerful in terms of reports you can build, how effective your product review is and makes for the most highly automated and accurate product replacement when it comes to advice.
Depending on the document or report it can be great to include this information with your insurance data so you are givining them an accurate picture of what their policy or cover is all about.
To do this you can use the following coding to pull through any options that have been listed for each cover type:
<:for item in $client.insurance_by_cover.filter('policy_status=Inforce'):>
<:for item2 in item.covers('i'):>
<:for opt in item2.options_list():>
<:if str(opt['response'])=='Yes':>
<:=str(opt['name']):><:if len(opt['parameters'])>0:> (<:=opt['parameters'][0]['response']:>)<:end:>
<:end:>
<:end:>
<:end:>
<:end:>
# Accidental Benefits (Basic)
# Claims Indexation
# Critical Conditions
# Future Insurability – Income
Xplan Policy Information Risk Researcher Options
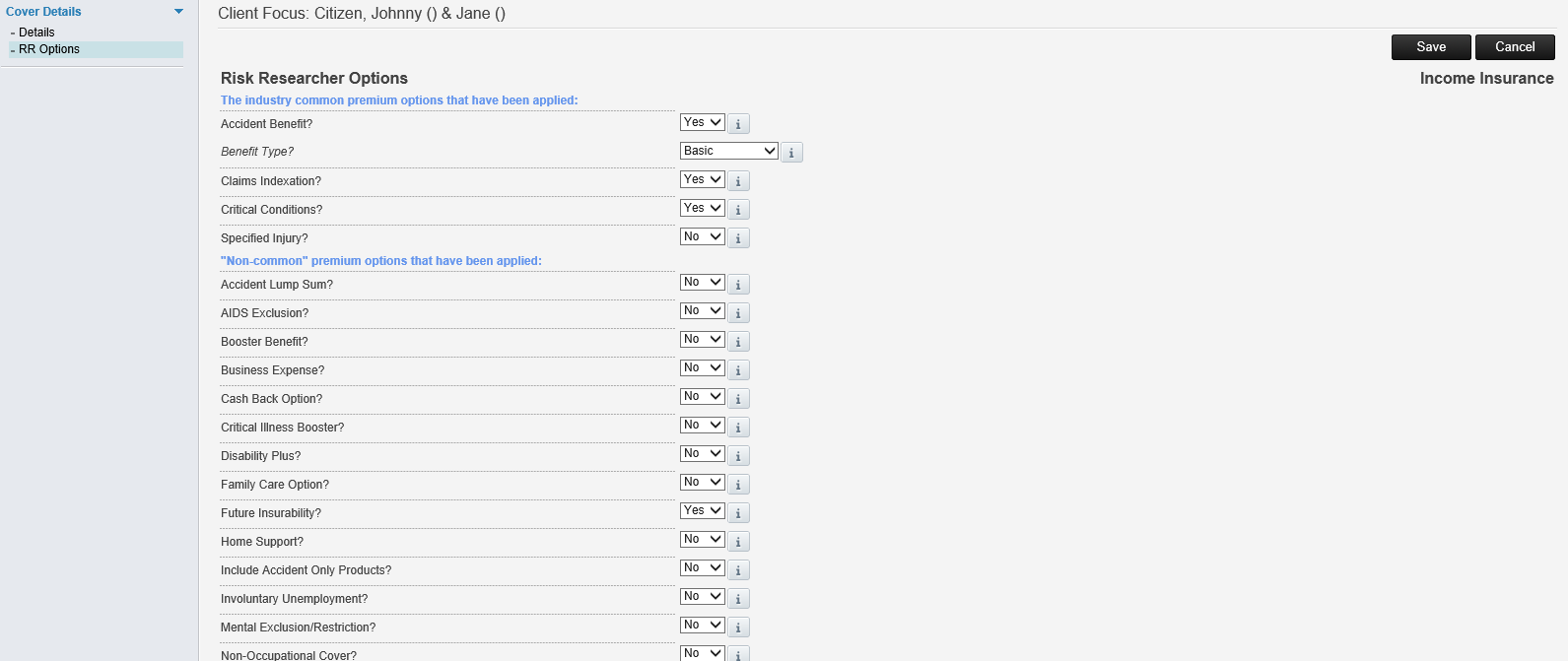
Xplan Policy Information Risk Researcher Options
Other methodologies
From other documents you might see a slightly different variation on the coding above.
Something like this:
<:for item in $client.insurance_by_cover.filter(‘policy_status=Inforce’):>
<:for item2 in $client.insurance:>
<:if (int(item2.linked_policy.value) == item.index) and (item2.type_group.value==’l’):>
<:end:>
<:end:>
<:end:>
- $client.insurance stores all of the insurance information but in a less structured way than the header approaches (by_policy, by_cover, all_insurance_group) but it also contains the cover information just like .covers()
- item.index is the unique number for the policy we’re currently looped into and item2.linked_policy.value is the same number but stored in each underlying cover for that policy. So the first part here is linking them together to ensure the cover data we are going to merge from $client.insurance is equal to the policy we’ve currently looped into.
- item2.type_group.value==’l’ is just ensuring this is the Life group similarly to what you’ve seen all above.
Just two different ways of achieving the same thing, likely because in older versions of Xplan the .covers() element didn’t have access to as much of the data as you could access in $client.insurance. Whilst not necessary, the linking of the item and item2 indexes can still be a good check and balance to keep in. If you add severity insurance into a merge loop (if anyone uses it?) you will need further redundancy otherwise in 2.13 and 2.14 you will find it causes your merge to double up.
<:for item in [policy for policy in $client.insurance_by_cover if str(policy.policy_status.value) in [‘Inforce’, ‘Existing’]]:># A lot of redundancy but we will still get the desired result and this will stop the current issue with severity based insurance included in loops
<:for item2 in item.covers(‘l’):>
<:if (int(item2.linked_policy.value) == item.index) and (item2.life_insured.value==$client.entity_id) and (item2.type_group.value==’l’):>
<:end:>
<:end:>
<:end:>
Sample documents
Below is a section of sample document showing some of the basic documents where we use this data.
Conclusion
This was a monster article but hopefully we’ve covered off the numerous elements, data storage, considerations and the many ways to code out that existing insurance information.
If you find anything has been missed or have suggestions to improve the article don’t hesitate to let us know.


